• 弱监督学习是机器学习领域中的一个分支,与传统监督学习相比,其用于训练模型的
数据是有限的、含有噪声的或者标注是不准确的。由于缺少有效的监督信息,因此期
望机器学习技术能够在弱的监督情况下能主动学习有效的数据特征表示。
按照数据的标注程度分类:
•不完全监督:全部训练数据中只有一个子集带有监督标签。比如,基于医学图像的疾病识别与筛查任务中,
具有精确标注的医学图像数量很少,大部分医学影像数据是没有被标注的。
•不确切监督:只给出数据的粗粒度标签。以基于医学影像的疾病识别与筛查任务为例,研究人员基于医学影
像开发计算机辅助诊断算法,需要大量都有精准标注的医学图像,特别是病灶区域标注。然而,由于医生的
精力有限和数据标注难度大,医生通常只给出单张医学图像是否存在异常区域,即图像级标注,而不是对医
学影像中病理区域进行标注,即像素级标注或对象级标注。
•不准确监督:针对的问题是给定的标签并不总是真实的情况。以基于医学图像的疾病识别与筛查任务为例,
其中医学影像人工标注质量很大程度依赖于阅片医生的知识、工作强度、经验以及接受的临床训练,这些都
可能会使得给定的标签并不总是真实的,特别是针对一些难以被准确分类的医学影像。
按照数据的学习方法分类:
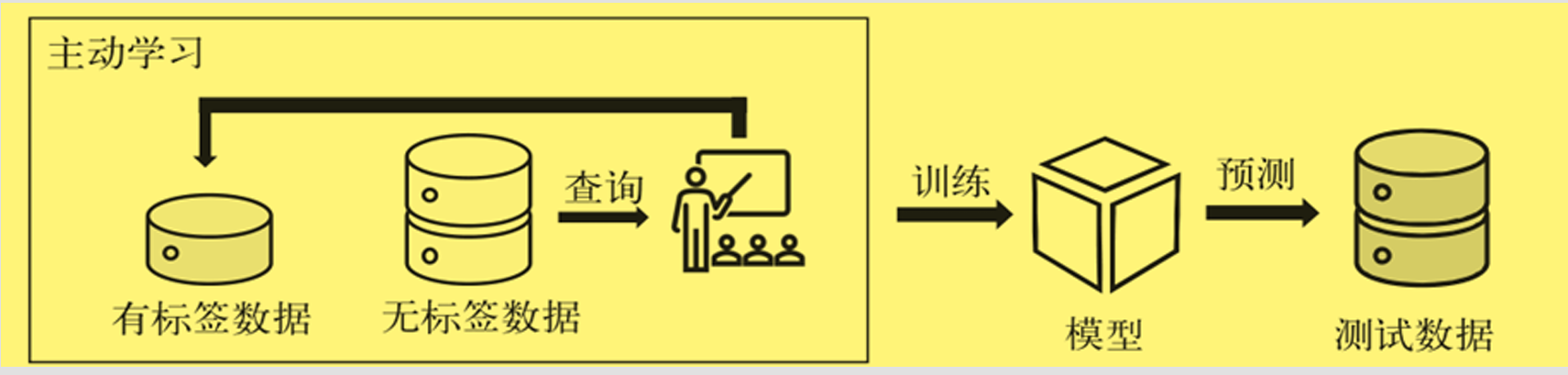
一、主动学习
通过机器学习的方法获取到那些比较“难”分类的样本数据,用人工的方式进行标注,然后将人工标注得到的数据再次进行训练,提高模型性能
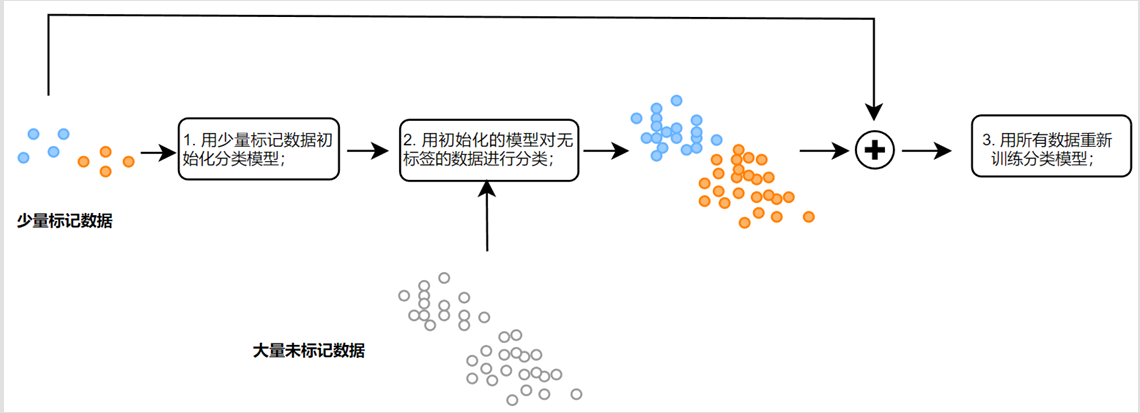
二、半监督学习
先用少量的标注数据训练模型;再用初始化的模型对无标签的数据进行标注,得到伪标签;最后用所有数据,包括有标签的数据和得到伪标签的数据,一起对模型进行训练。
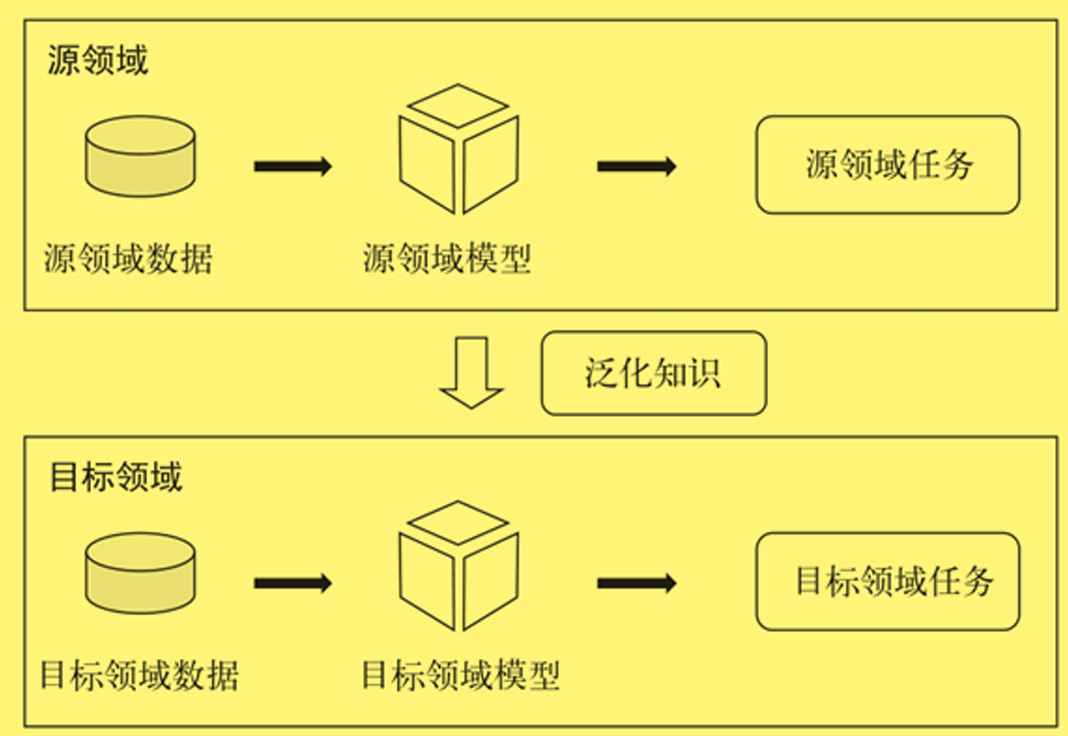
三、迁移学习
目标任务的训练数据较少,而有一个相关任务有大量的训练数据, 可以学习某些可以泛化的知识, 这些知识对目标任务会有一定的帮助。
四、多示例学习
定义“包”为多个示例的集合,学习者不是接收一组单独标记的实例,而是接收一组带标签的包,每个包拥有多个实例。
在多实例二进制分类的简单情况下,如果包中的所有实例都是否定的,则可以将包标记为否定。另一方面,如果包中只要至少有一个是正面的,则包被标记为阳性
