直接开门见山吧,卷积神经网络相较于我们博客之前所讨论的普通神经网络的根本区别在于引入了多个卷积层+池化层, 通过提取图像特征,将其量化为像反向传播里那样可供计算的权重,去识别图像。
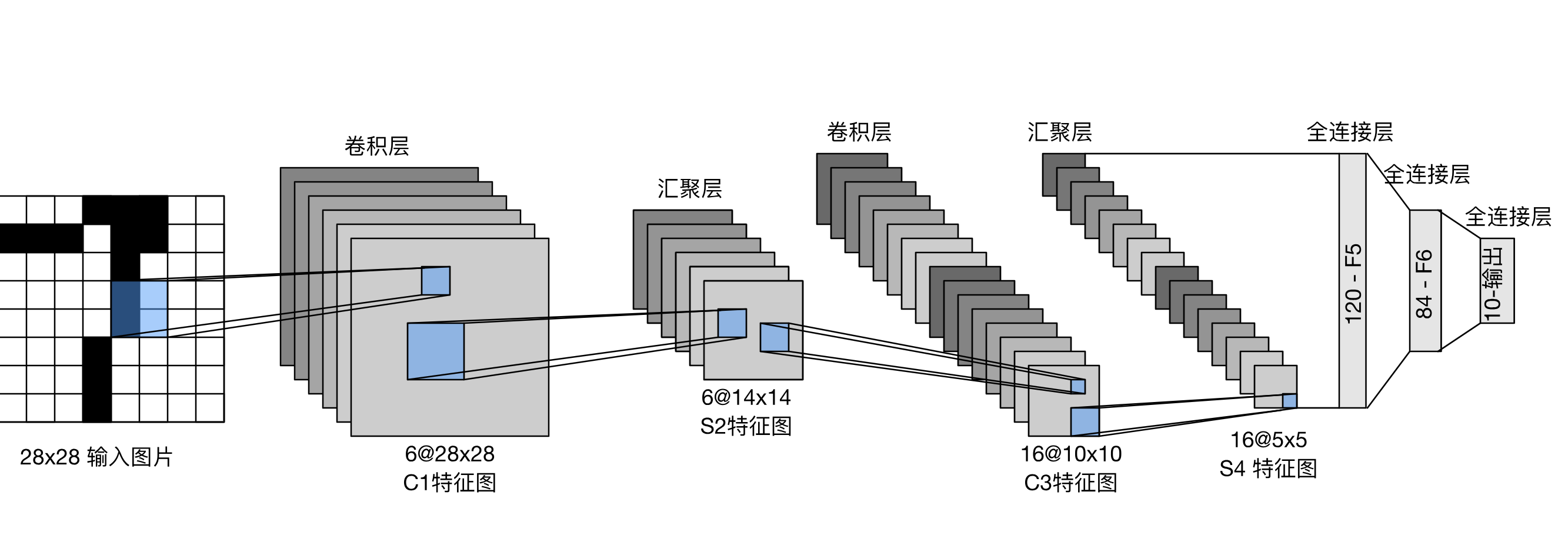
一、卷积层
卷积层是卷积神经网络的核心组件,它通过使用卷积核(也称为滤波器)来提取输入数据中的特征。 我们知道图像其实可以看作一个大的矩阵,每个像素点都有一个对应的数值元素。 而卷积核是一个小矩阵,它在输入数据上滑动,计算每个位置上的点积,从而生成一个新的特征图。 比如一个最简单的3×3卷积核,每一个元素均为1,那么它在输入数据上滑动,相当于把每一个经过的3×3区域的像素值求平均然后映射到下一层去, 本质上是“模糊化”操作,相当于给原图上了层马赛克。 而在一些更为复杂的情况下,卷积核会有不同的权重,假设一个2×2的卷积核从左往右,从上往下依次是1、-2、3、4,卷积核所要处理的区域是12、73、56、-14, 注意,卷积计算是翻转后求点积,即卷积核处理后会输出12×4+73×3+56×(-2)+(-14)×4=99。
卷积核的大小和数量可以根据任务的需求进行调整。比如你想提取狗图像特征,你可以调整权重,每一个不同的权重矩阵可以对应眼睛特征、毛发特征、鼻子特征等等等
这里给出相关项目的网址:https://setosa.io/ev/image-kernels/ 可以很清晰了解不同卷积核在卷积处理中带来的不同影响
接下来是两个细节问题:
填充(padding):我们注意到,当一个卷积核沿着一个图像滑动下来,由于边缘一圈的像素只能被算一次,导致卷积出来的新图像较原图像“瘦”了一圈, 特征信息损失。一般的解决方案是在原图外加一圈像素值为0的“padding”,这样,卷积出来的图像将和原图尺寸一致。这个方法也可以拓展,如果我们想在卷积过程中放大图像, 我们可以在外面多加几圈padding,甚至还可以在内部填充,相当于一定程度上“稀释”或者说“分摊”原有的像素值,即“上采样”
步长(stride):这个参数的作用是控制卷积核在输入图像上滑动的步长,即每次滑动的距离。通常情况下,步长为1,即每次滑动一个像素。调整这个变量, 也会影响我们对图像的处理模式,是放大图像得到更多特征,还是缩小图像便于并行计算。
二、池化层
池化层是卷积神经网络中用于减少特征图尺寸和减少参数数量的一种方法。它通过对输入数据进行下采样,从而减少特征图的尺寸。 常见的池化操作包括最大池化和平均池化,都相当于压缩了输入图像的信息:
最大池化:在每个池化窗口内,选择最大值作为输出,如一个2×2的池化窗口里面有1、2、3、4四个元素,处理后输出4到下一层对应位置。
平均池化:在每个池化窗口内,取平均值作为输出,如一个2×2的池化窗口里面有1、2、3、4四个元素,处理后输出2.5到下一层。
卷积+池化部分的更多细节
在处理过程中,我们往往会引入激活函数,比如卷积后的值小于0则取0,大于0则不变,这些激活函数能够优化图像的处理方案。
另外,在实际应用中,我们往往会用不同的卷积核去处理同一个图像,相当于突出了这个图像的每一个不同的特征,进而得到比输入的原图像更多的图像, 这些图像可以被池化层进一步处理,池化层会将这些图像进一步压缩,得到一个更小的特征图,然后不断重复卷积池化卷积池化......我们将得到越来越多的 同时尺寸也越来越小的图像,这些图像我们凭借肉眼已经几乎判断不出来它们是原图像加工后的产物,但他们都对应着原图像的某一个局部特征
唉,这样说太抽象了,这里直接给出斯坦福某位开发者贡献出来的CNN可视化网站(复刻杨立昆识别手写体数字):https://adamharley.com/nn_vis/cnn/2d.html

显然,在最初的层级中肉眼依然可以辨别手写2的特征,越往后,2的特征对人眼越抽象,对计算机却越具体
三、全连接层
经历上述操作后,我们得到了a个特征图(即通道),b×c的尺寸,因此输入全连接层的是一个三维的数据,但神经网络对数据处理是一维的,因此我们把这个三维数据,相当于一个 长方体,里的每个小正方体拿出来排成一排,每一个小正方体的数据作为一个神经元,然后就是普通的神经网络训练过程。
比如说输入的一维数据为(2,1,3),训练处理过程会找到六个权重,组成一个2×3的矩阵,然后就是矩阵向量乘法,对得到的新向量作softmax函数处理就知道各个数字的概率了
好了,既然你已经知道卷积神经网络的基本算法了,下面附上南科大上完这门课后布置的作业,你可以试一下
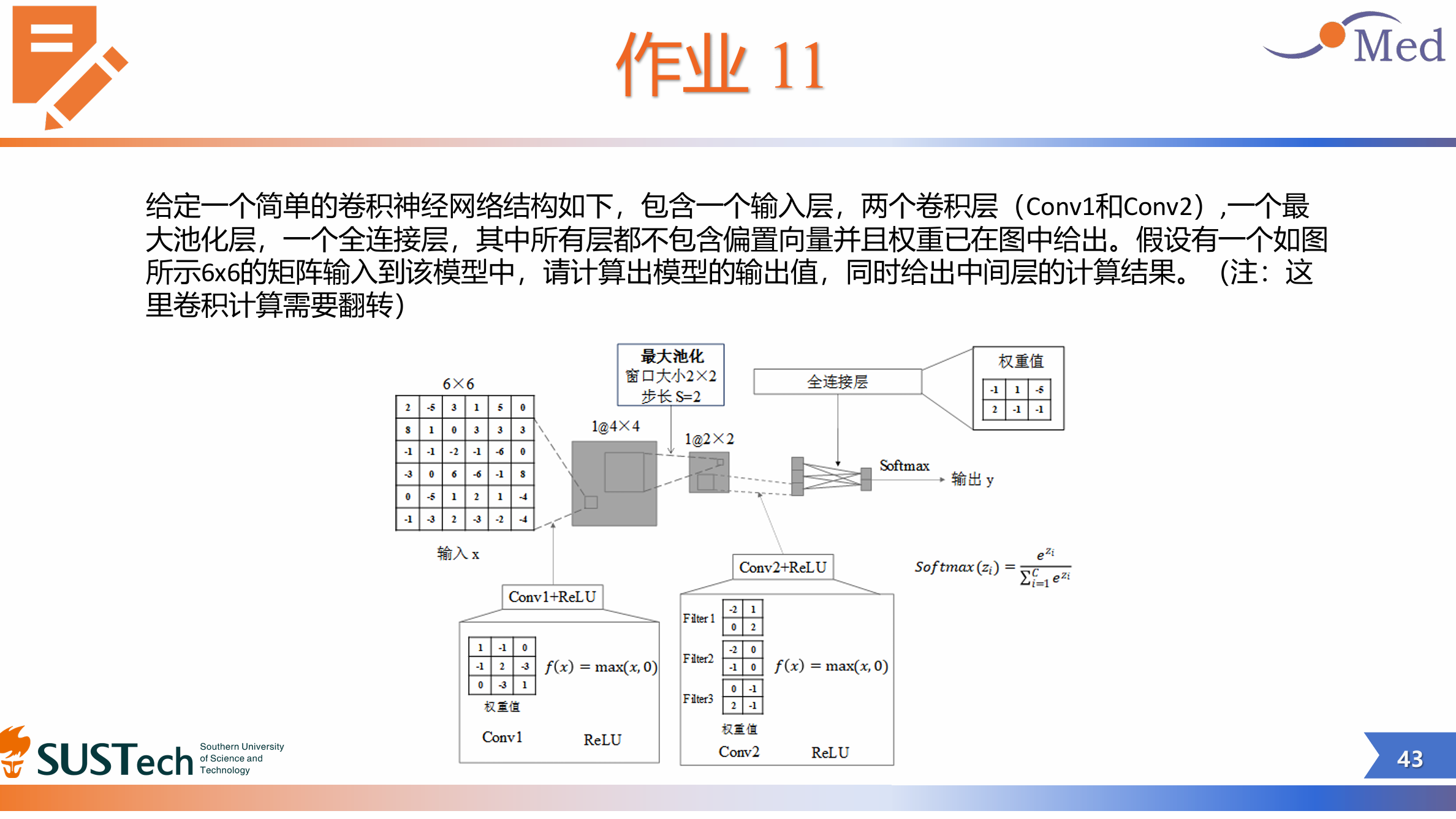
之后,我会更新卷积神经网络的具体代码实现,敬请期待~~