2009年李飞飞团队领导建立的大规模标注数据集ImageNet极大推动计算机视觉及机器学习方面的研究进展,该数据集包含数千万张跨越数万个类别的手动标注图像, 为有效训练更深更复杂的卷积神经网络模型提供了必要的海量数据。自 2010 年以来,ImageNet 项目每年都会举办一项软件竞赛,即 ImageNet 大规模视觉识别挑战赛 ( ILSVRC ),其中软件程序竞相正确分类和检测对象和场景。 最初,传统机器学习方法在2010年和2011年获胜,但在2012年,名为AlexNet的卷积神经网络(CNN)在 2012 ImageNet 挑战赛中取得了 15.3% 的 Top-5 错误率,比亚军低了 10.8 个百分点以上。 卷积神经网络的可行性源于训练过程中使用图形处理单元(GPU) ,这是深度学习革命的重要组成部分。 《经济学人》报道称:“突然之间,人们开始关注它,不仅在人工智能领域,而且在整个科技行业。”
该模型由多伦多大学的Alex Krizhevsky与Ilya Sutskever及其博士生导师Geoffrey Hinton于 2012 年合作开发,包含 6000 万个参数和 65 万个神经元。 相较Lenet该神经网络在深度方面有着显著的提高(毕竟这个时候GPU被发明了出来),具体来说AlexNet 在 GTX 580 GPU 上训练,该 GPU 仅有 3 GB 内存,无法容纳整个网络。 因此,网络被拆分到 2 个 GPU 上,每个 GPU 上分别承载一半的神经元。
如图所示AlexNet 由 5 个卷积层、3 个最大池化层、2 个标准化层、2 个完全连接层和 1 个 SoftMax 层组成
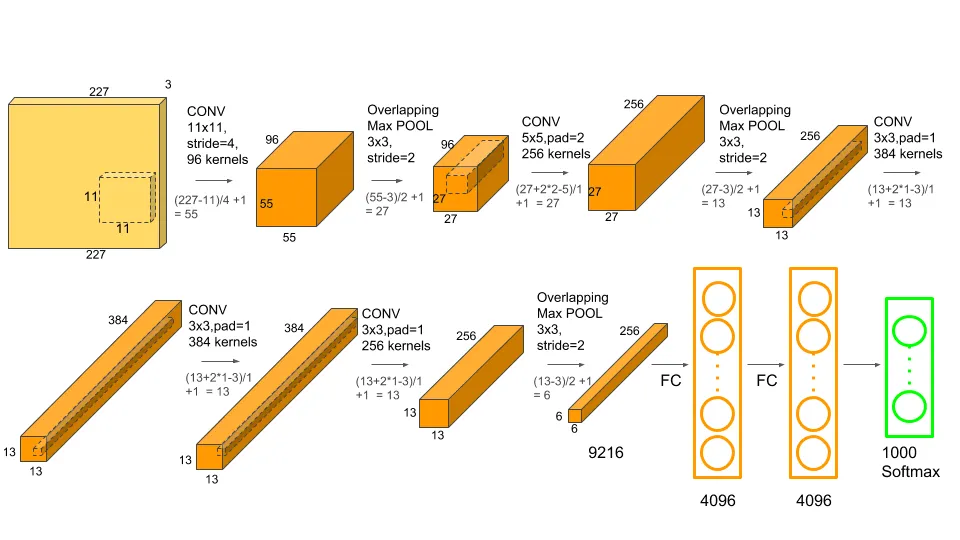
*227是经padding操作后的宽度/高度
Alexnet相较Lenet在以下多个方面做出了改进:
1.引入了 ReLU 激活函数,取代了 sigmoid 或 tanh 等传统激活函数。 传统激活函数常常存在梯度消失问题,即在反向传播过程中梯度变得极其微小,接近于零时,参数的更新幅度就会变得非常小, 甚至几乎为零。这意味着网络前部的层(靠近输入层的层)的权重几乎无法得到更新,学习过程停滞,模型无法有效地从数据中学习到深层次的特征, 从而导致训练效果不佳,甚至无法收敛。这就是所谓的“梯度消失”问题。而ReLU 通过缓解梯度消失问题并加速收敛,实现了更快、更高效的训练。
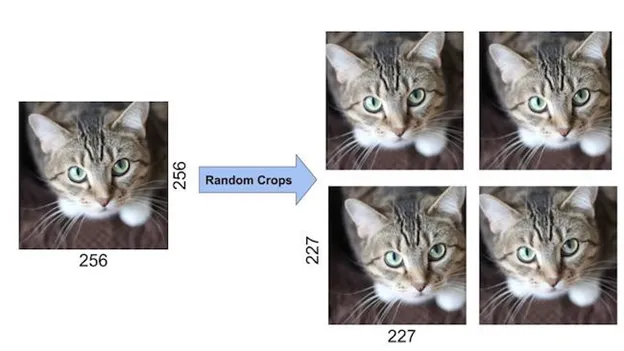
2.引入数据增广扩充数据集。如下图1演示的翻转直接让数据集里的照片翻倍,又或者随机裁剪,如下图2把一张大图随机裁剪成符合输入图像大小要求的图片

3.引入了dropout算法,该算法于12年被Hinton提出,并被首次应用于Alexnet。 Dropout可以作为训练深度神经网络的一种trick供选择,在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象
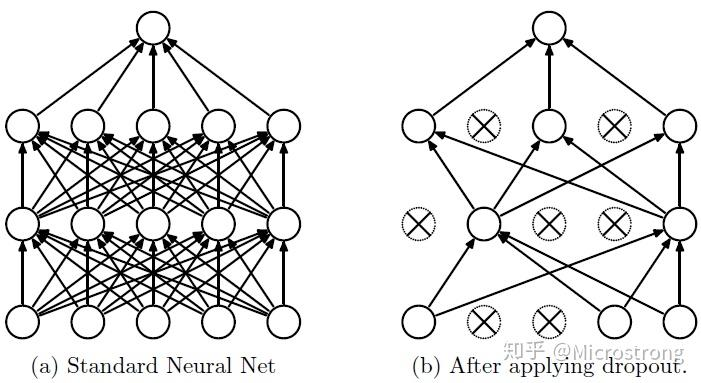
有关dropout的详细解释可参见该知乎文章:https://zhuanlan.zhihu.com/p/38200980
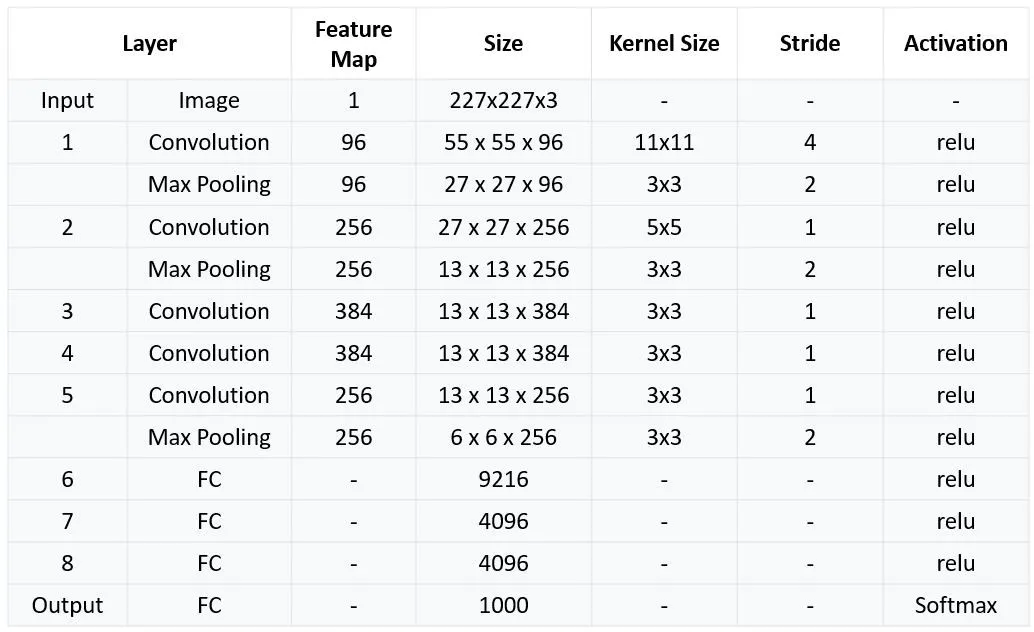
最后我们总结一下Alexnet的结构:
延申阅读:https://medium.com/@siddheshb008/alexnet-architecture-explained-b6240c528bd5
https://cdanielaam.medium.com/building-your-first-convolution-neural-network-alexnet-e337921f0355